…and static site generators more generally.
This is a summary of a presentation on Pelican I presented on May 9, 2016. It covers some of the building blocks of Pelican, and then provides several examples of Pelican in use.
As a personal note, this presentation follows my own path of learning and growth with these technologies. I should note that I’m not a programmer or a web developer by trade; that everything I’ve done with Pelican has been as a part of another job or for personal projects. I hope to show you very practical applications of Pelican, rather than theoretical projects.
Intended Audience
I’m assuming:
- you know the basics of HTML (or are willing to learn them on your own)
- comfortable with Python, and have it installed on your machine
- you’ve worked with Git and Github
HTML Was Simple
There was a time when you could write HTML in Notepad (or really any text editor). Your HTML file might have looked like this:
<html>
<head>
<title>My Simple Webpage</title>
</head>
<body>
<p>I can write anything I want here. Add some <b>bold</b> or
<i>italics</i> text. For everything else, I'll send you to
<a href="https://www.google.com">Google</a>!</p>
</body>
</html>
which would turn into something like this:
I can write anything I want here. Add some bold or italics text. For everything else, I’ll send you to Google!
This is foundational! It is true that most the HTML we generate, or want to generate, is more complicated that this, but understanding basic HTML is very helpful to make adjustments to any website.
On a personal note, I found the idea of HTML simple to grasp as I was already familiar with WordPerfect’s Reveal Codes.
The LAMP Stack
Today, many (most?) websites are run on a combination of technologies referred to as the “LAMP Stack”:
- Linux (Operating System)
- Apache (Web Server)
- MySQL (Database/data store)
- PHP (Scripting Language)
This combination provides the basis for a Dynamic Website.
This setup is hugely common:
- Linux is used by 36% of websites (source)
- Apache is used by 53% of websites (source)
- PHP is used on 82% of websites using a scripting language (source)
WordPress is (probably) the most common use of the LAMP stack, and powers 26% of all websites! (source)
Downtime

In recent years, various technologies have stepped forward to replace parts of the LAMP stack (such as Nginx for the webserver, multiple options for databases, or even Python as the scripting language), but the basic combination of pieces remains largely the same. The combination of all these moving parts increases complexity, and can lead to downtime for myriad reasons. Consider Twitter’s Fail Whale (above). This is the image Twitter used to show when some part of their website wasn’t working as expected. The fact that this image would enter into popular culture is a testament to how hard it is to manage a LAMP stack as scale.
This is an area that Pelican, and static site generators more generally, aim to solve by eliminating the need for a database and scripting language on your webserver.
Competitors
This presentation is about Pelican, but Pelican, of course, is no the only option. Some of the competitors include:
- for dynamically generated sites:
- Wordpress — written in PHP, one of the most popular ways to run a website. Personally, probably because I wasn’t working full time with it, I seemed that every time I touched it I was constantly trying to keep up with the security updates and trying to make it run faster. The advantage of WordPress is that it’s hugely common, so it’s (relatively) easy to find people to work on your site for you. WordPress’ out-of-the-box experience is also one of the best on this list, making it easy for non-technical people to get it up and running.
- Django — written in Python. I don’t have much personal experience with Django.
- for statically generated sites:
- Jekyll — written in Ruby. This is the default provided by Github’s pages. When I considered it, now a couple of years ago, I couldn’t get it to run on Windows.
- Octopress — a fork of Jekyll, written to provide expanded features, still in Ruby.
- Sphinx — written in Python, originally designed for documenting Python source code. Very powerful for writing general content (and probably more powerful that Pelican), I haven’t found a way I was satisfied with to use it with blog content.
- hand-crafted, or roll-your-own — the principals behind a static site generator are rather simple, so to roll you own could maybe be done as a weekend project.
- and 100’s of other options…
Your situation is probably different than mine, but I considered all of the above listed options, and for various reasons, decided Pelican would be the best fit for me.
Pelican Building Blocks
We’re almost ready to jump into Pelican proper, but there’s a few more things to introduce before we jump:
- markup languages: Markdown, Restructured Text (ReST), and HTML
- tempalating: Jinja
- layout: Bootstrap
Markdown
Markdown was created to be a lightweight markup language what remains readable even as the plain-text version. It was modelled after the conversions used in plain text emails and Usenet.
Markdown is used many places around the web (Github, Stack Overflow, etc). There are several dialects, but the core of the language is common and well-understood.
An example markdown Pelican post:
Title: My super title
Date: 2010-12-03 10:20
Modified: 2010-12-05 19:30
Category: Python
Tags: pelican, publishing
Slug: my-super-post
Authors: Alexis Metaireau, Conan Doyle
Summary: Short version for index and feeds
This is the content of my super blog post.

```python
# python code block
print("A literal block directive explicitly marked as python code")
```
A sentence with links to [Wikipedia](http://www.wikipedia.org/) and the
[Linux kernel archive](http://www.kernel.org/).
Restructured Text
Sometimes shorted as ReST or RST, this was originally created for documenting the Python standard library. As such, it has great Python support (but somewhat limited support in other programming languages), and a well-defined specification.
An example Restructured Text Pelican post:
My super title
##############
:date: 2010-10-03 10:20
:modified: 2010-10-04 18:40
:tags: thats, awesome
:category: yeah
:slug: my-super-post
:authors: Alexis Metaireau, Conan Doyle
:summary: Short version for index and feeds
This will be turned into :abbr:`HTML (HyperText Markup Language)`.
.. image:: /path/to/image.jpg
.. code-block:: python
:classprefix: pgcss
:linenos: table
:linenostart: 153
print("A literal block directive explicitly marked as python code")
A sentence with links to Wikipedia_ and the `Linux kernel archive`_.
.. _Wikipedia: http://www.wikipedia.org/
.. _Linux kernel archive: http://www.kernel.org/
HTML
Pelican can also use HTML files as a source. Post metadata is read from the pages meta tags.
An example HTML Pelican post:
<html>
<head>
<title>My super title</title>
<meta name="tags" content="thats, awesome" />
<meta name="date" content="2012-07-09 22:28" />
<meta name="modified" content="2012-07-10 20:14" />
<meta name="category" content="yeah" />
<meta name="authors" content="Alexis Métaireau, Conan Doyle" />
<meta name="summary" content="Short version for index and feeds" />
</head>
<body>
This is the content of my super blog post.
</body>
</html>
Jinja
Jinja is a templating language (we technically use Jinja2). Pelican uses this to define the templates that the blog content is then dropped into.
Jinja isn’t something you need to understand on day 1 to get your Pelican site up and running, but eventually you’ll probably want to adjust your theme, and for that you’ll need some Jinja.
A basic Jinja template:
layout.html
<html>
<head>
<title>{% block title %}{% endblock %}</title>
</head>
<body>
{% block body %}{% endblock %}
</body>
</html>
users.html
{% extends "layout.html" %}
{% block title -%}
All Users
{%- endblock %}
{% block body %}
<ul>
{% for user in users %}
<li><a href="{{ user.url }}">{{ user.username }}</a></li>
{% endfor %}
</ul>
{% endblock %}
A more advanced Jinja template:
archives.html
{% extends "base.html" %}
{% block title %}Archives - {{ SITENAME }}{% endblock %}
{% block breadcrumbs %}
{% if DISPLAY_BREADCRUMBS %}
<ol class="breadcrumb">
<li><a href="{{ SITEURL }}" title="{{ SITENAME }}"><i class="fa fa-home fa-lg"></i></a></li>
<li class="active">Archives</li>
</ol>
{% endif %}
{% endblock %}
{% block content %}
<section id="content">
<h1>Archives for {{ SITENAME }}</h1>
<div id="archives">
{%- set last_year = None -%}
{%- set last_month = None -%}
{%- set last_day = None -%}
{% for article in dates %}
<div class="row">
{% if article.date.year != last_year %}
{% if last_year != None -%}
<div class="archives-spacer col-xs-12"> </div>
<div class="archives-spacer col-xs-12"> </div>
{%- endif %}
<div class="archives-date archives-year col-xs-4 col-sm-2 col-sm-offset-2">
<a name="{{ article.date.year }}"></a>
{{- article.date.year -}}
</div>
<div class="archives-title col-xs-7 col-sm-6">
</div>
{%- set last_year = article.date.year -%}
{%- set last_month = None -%}
{%- set last_day = None -%}
{% endif %}
{% if article.date.month != last_month %}
{% if last_month != None -%}
<div class="archives-spacer col-xs-12"> </div>
{%- endif %}
<div class="archives-date archives-month col-xs-4 col-sm-2 col-sm-offset-2">
<a name="{{ article.date.year }}-{{ article.date.month }}"></a>
{{- article.date|strftime('%B') -}}
</div>
<div class="archives-title col-xs-7 col-sm-6">
</div>
{%- set last_month = article.date.month -%}
{%- set last_day = None -%}
{% endif %}
<div class="archives-date categories-timestamp col-xs-4 col-sm-2 col-sm-offset-2">
{%- if last_day != article.date.day %}
<time datetime="{{ article.date.isoformat() }}">{{ article.date | strftime('%a %-d') }}</time>
{% else -%}
{%- endif -%}
</div>
<div class="archives-title col-xs-7 col-sm-6">
<a href="{{ SITEURL }}/{{ article.url }}">{{ article.title }}</a>
{% if article.subtitle %}<br />{{ article.subtitle }}{% endif %}
</div>
{%- set last_day = article.date.day %}
</div>
{% endfor %}
</div>
</section>
{% endblock %}
Responsive Design
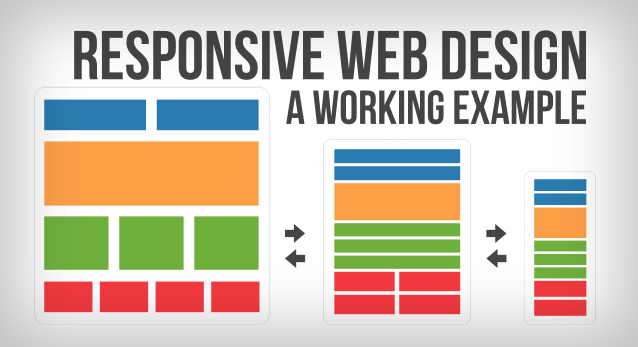
Responsive Design is a way a designing a website so that it’s layout will change between mobile and desktop browsers, but the actual content doesn’t change. For this, we can use Bootstrap.
Pelican
Quickstart
Yes, that took long enough. But let’s jump into using Pelican. We can use
pelican-quickstart to quickly create a skeleton site.
First, let’s install Pelican. We also install Markdown, as it’s not automatically installed.
C:> pip install pelican markdown
[...]
C:> pelican-quickstart

And now you have a basic Pelican site.
(Basic) File Structure
yourproject/
├── content/ # articles and pages go here
├── output/
├── develop_server.sh
├── fabfile.py
├── Makefile
├── pelicanconf.py # Main settings file
└── publishconf.py # Settings to use when ready to publish
Internal Links
Pelican allows us to specify links between files. To do so, we use the source content hierarchy rather than the generated hierarchy.
For example, if your site is laid out like this:
yourproject/
├── content/
│ ├── article1.rst
│ ├── cat/
│ │ └── article2.md
│ ├── images
│ │ └── han.jpg
│ ├── pages/
│ │ ├── about.md
│ │ └── (other articles)
│ └── (other articles)
├── output
├── develop_server.sh
├── fabfile.py
├── Makefile
├── pelicanconf.py # Main settings file
└── publishconf.py # Settings to use when ready to publish
so then you would create your entry (with links) like this:
article2.md
Title: The second article
Date: 2012-12-01 10:02
See below intra-site link examples in Markdown format.
[a link relative to the current file]({static}../article1.rst)
[a link relative to the content root]({static}/article1.rst)

Quirks
Pelican does have a couple of other quirks:
- slugs for articles and pages must be unique. Duplicate slugs are assumed to be translations.
- Pelican itself is under the AGPL. For practical purposes, if you are just running Pelican for yourself and pushing the output to a server, I don’t think this is an issue. If you are running a service that use Pelican to generate sites under the hood, there may be a requirement to provide your full source code. (That said, get your own legal advice if this is really a concern.)
Using GitHub pages for hosting also has a couple of quirks too:
- use the master branch for your personal or organization homepage, and the gh-pages branch for project pages (see GitHub help for more details, although they have a couple more options now).
- project pages will show up as a sub-directory of your main website. (i.e. my colourettu project’s generated site lives at minchin.ca/colourettu/)
- GitHub pages will automatically run your site through Jekyll before
publishing it. I haven’t had this cause problems directly, but it does add a
delay between pushing your site to GitHub and having it go live. To remove
this, add a
.nojekyllfile to the root of your project. I created a plugin (minchin.pelican.plugins.nojekyll) to take care of this automatically. - you have use a custom domain for your GitHub pages. Create a
CNAMEfile that just contains your domain name, and change your DNS settings to point to GitHub to enable this. (See GitHub Help for full details.) I created a plugin (CName) to take care of this automatically.
Pelican Configuration — pelicanconf.py
Your configuration file for Pelican are regular Python files. This means you can run Python function and import other Python files.
Pelican settings generally separated between development (pelicanconf.py) and
production (publishconf.py, which usually imports pelicanconf.py).
An example pelicanconf.py:
#!/usr/bin/env python
# -*- coding: utf-8 -*- #
from __future__ import unicode_literals
AUTHOR = 'Wm Minchin'
SITENAME = 'Introduction to Pelican'
SITEURL = ''
PATH = 'content'
ARTICLE_PATHS = ['posts']
PAGE_PATHS = ['.']
TIMEZONE = 'America/Edmonton'
DEFAULT_LANG = 'en'
# Feed generation is usually not desired when developing
FEED_ALL_ATOM = None
CATEGORY_FEED_ATOM = None
TRANSLATION_FEED_ATOM = None
AUTHOR_FEED_ATOM = None
AUTHOR_FEED_RSS = None
# Blogroll
LINKS = (('Pelican', 'http://getpelican.com/'),
('Python.org', 'http://python.org/'),
('Jinja2', 'http://jinja.pocoo.org/'),
('You can modify those links in your config file', '#'),)
# Social widget
SOCIAL = (('You can add links in your config file', '#'),
('Another social link', '#'),)
DEFAULT_PAGINATION = 10
and an example publishconf.py:
#!/usr/bin/env python
# -*- coding: utf-8 -*- #
from __future__ import unicode_literals
# This file is only used if you use `make publish` or
# explicitly specify it as your config file.
import os
import sys
sys.path.append(os.curdir)
from pelicanconf import *
SITEURL = 'http://minchin.ca'
RELATIVE_URLS = False
FEED_ALL_ATOM = 'feeds/all.atom.xml'
CATEGORY_FEED_ATOM = 'feeds/%s.atom.xml'
DELETE_OUTPUT_DIRECTORY = True
# Following items are often useful when publishing
#DISQUS_SITENAME = ""
#GOOGLE_ANALYTICS = ""
Overview of Examples
Below are four examples of sites I have build with Pelican. I have included full configuration files here, which makes this post particularly long. However, I hope having full working examples will help you get started on your own site.
If the code below doesn’t work, please let me know so I can fix it; Pelican does tweak its setting from time to time.
The four examples are:
- jnrl — a have a personal-use site where I display the notes I keep for myself.
- Burst Energy — a full production site I used to be responsible. In this case, it was mostly content pages rather than blog posts (although there was a small “News” section). I have also included some of the support code I used to generate pieces used by the website, and to format the generated site for deployment.
- Minchin.ca — my personal website (available at minchin.ca).
- Minchin Genealogy — a site of my personal genealogy. This poses certain issues due to it’s size (over 11,000 pages), but Pelican can still deal with it. I have included the build script for this site below, and you will see that Pelican is just one step — the data is cleaned before it is fed to Pelican the resulting site is also adjusted. (Available at minchin.ca/genealogy).
Not listed here, but this site (blog.minchin.ca), is also generated with Pelican, and separately from the main part of Minchin.ca. The code for the site is posted to GitHub and open to review.
Example 1 — Jrnl
In this example, I use Pelican to display notes that I store in jrnl. I use jrnl to export these notes to individual markdown files, which serve as the source files for Pelican. I uses a separate Python program (prjct) and a custom Pelican template to include my todo list items on tag pages.
Batch Script
I use this script to (re-)generate the site from the Windows command line.
@ECHO off
@ECHO Delete old JRNL export
del S:\Documents\jrnl-pelican\content\*.md
:: Export from JRNL
jrnl --export yaml -o S:\Documents\jrnl-pelican\content\
jrnl dayone --export yaml -o S:\Documents\jrnl-pelican\content\
:: Export from PRJCT
prjct project_entry S:\Documents\jrnl-pelican\content\all_projects.md
:: Pelican
cd S:\Documents\jrnl-pelican
@ECHO Running Pelican...
pelican -s publishconf.py
robocopy S:\Documents\jrnl-pelican\output\ \\myserver\web\jrnl\ /MIR /nfl /ndl
Sample JRNL Exported Entry
title: Kurt Vonnegut's 8 Tips on How to Write a Great Story
date: 2012-10-15 14:04
stared: False
tags: whitespace, bookmarks, writing, writing_tips
**The Atlantic Home** --
Saturday, July 7, 2012 --
By Maria Popova --
[Source](http://www.theatlantic.com/entertainment/archive/2012/04/kurt-vonneguts-8-tips-on-how-to-write-a-great-story/255401/)
Why you should be cruel to your readers
The year of reading more and writing better is well underway with writing advice
the likes of David Ogilvy's 10 no-bullshit tips, Henry Miller's 11 commandments,
Jack Kerouac's 30 beliefs and techniques, John Steinbeck's 6 pointers, and
various invaluable insight from other great writers.
Now comes Kurt Vonnegut -- anarchist, Second Life dweller, imaginary interviewer
of the dead, sad soul -- with eight tips on how to write a good short story,
narrated by the author himself.
1. Use the time of a total stranger in such a way that he or she will not feel the time was wasted.
2. Give the reader at least one character he or she can root for.
3. Every character should want something, even if it is only a glass of water.
4. Every sentence must do one of two things—reveal character or advance the action.
5. Start as close to the end as possible.
6. Be a Sadist. No matter how sweet and innocent your leading characters, make awful things happen to them—in order that the reader may see what they are made of.
7. Write to please just one person. If you open a window and make love to the world, so to speak, your story will get pneumonia.
8. Give your readers as much information as possible as soon as possible. To hell with suspense. Readers should have such complete understanding of what is going on, where and why, that they could finish the story themselves, should cockroaches eat the last few pages.
Pelicanconf.py
This is my settings file:
#!/usr/bin/env python
# -*- coding: utf-8 -*- #
from __future__ import unicode_literals
import re
import prjct
# requires pymdown-extensions
AUTHOR = u'WM'
SITENAME = u'Jrnl Notebook'
SITEURL = ''
PATH = 'content'
CUSTOM_CSS = SITEURL + '_css/jrnl.css'
CACHE_CONTENT = True
LOAD_CACHE_CONTENT = True
CHECK_MODIFIED_METHOD = 'md5' # default is the file's modified time, which is
# useless for us because we keep regenerating
# the source files
TIMEZONE = 'America/Edmonton'
DEFAULT_LANG = u'en'
DEFAULT_DATE = 'fs'
# Feed generation is usually not desired when developing
FEED_ALL_ATOM = None
CATEGORY_FEED_ATOM = None
TRANSLATION_FEED_ATOM = None
DEFAULT_PAGINATION = 10
TYPOGRIFY = True
TYPOGRIFY_IGNORE_TAGS = ['code', 'pre', 'tt']
STATIC_PATHS = ['images', '_css']
THEME = 'themes/pelican-bootstrap3'
FAVICON = SITEURL + 'images/favicon.ico'
FAVICON_IE = SITEURL + 'images/favicon.ico'
SITELOGO = SITEURL + 'images/favicon-48.png'
ELEVATOR = False
BOOTSTRAP_THEME = 'superhero'
USE_PAGER = True
BOOTSTRAP_NAVBAR_INVERSE = True
DISPLAY_TAGS_INLINE = True
DISPLAY_BREADCRUMBS = True
# see https://pythonhosted.org/Markdown/reference.html#markdown
# format required for Pelican 3.7
MARKDOWN = {
'extension_configs': {
# set linenums=True for line numbers
# https://pythonhosted.org/Markdown/extensions/code_hilite.html
'markdown.extensions.codehilite': {'css_class': 'highlight'},
# on by default
# see https://pythonhosted.org/Markdown/extensions/extra.html
'markdown.extensions.extra': {},
'markdown.extensions.meta': {},
# https://facelessuser.github.io/pymdown-extensions/extensions/superfences/
'pymdownx.superfences': {},
# use single caret for superscript
# use double caret for insertion (underline?)
# https://facelessuser.github.io/pymdown-extensions/extensions/caret/
'pymdownx.caret': {},
# use single tildes for subscript
# use double tildes for deletion
# https://facelessuser.github.io/pymdown-extensions/extensions/tilde/
'pymdownx.tilde': {},
# https://pythonhosted.org/Markdown/extensions/smarty.html
'markdown.extensions.smarty': {},
# so MathJax equations (always) make it through
# https://facelessuser.github.io/pymdown-extensions/extensions/arithmatex/
'pymdownx.arithmatex': {},
# Auto-convert special symbols, like (tm) to ™
# https://facelessuser.github.io/pymdown-extensions/extensions/smartsymbols/
'pymdownx.smartsymbols': {},
},
'output_format': 'html5',
'lazy_ol': False,
}
# A list of metadata fields containing reST/Markdown content to be parsed and translated to HTML.
FORMATTED_FIELDS = ['title', 'summary']
PLUGIN_PATHS = ['../GitHub/pelican-plugins', ]
PLUGINS = ['tipue_search',
'tag_cloud',
'prjct.titlecase', # titlecase Jinja filter
]
TAG_CLOUD_STEPS = 4
TAG_CLOUD_MAX_ITEMS = 100
prjct_release = str(prjct.__version__)
p = re.compile('\d+\.\d+(\.\d+)?')
prjct_versionmatch = p.match(prjct_release)
prjct_version = prjct_versionmatch.group()
PRJCT = True
PRJCT_TODO, PRJCT_DONE = prjct.todo_export.to_html_dicts(prjct.config.load())
PRJCT_PROJECTS = prjct.todo_export.project_list()
PRJCT_DESC = prjct.descriptions.to_html_dict(prjct.config.load(), MD_EXTENSIONS)
PRJCT_VERSION = prjct_version
PRJCT_URL = prjct.__url__
PAGE_URL = '{slug}/'
PAGE_SAVE_AS = '{slug}/index.html'
TAGS_URL = 'tags/'
TAGS_SAVE_AS = 'tags/index.html'
TAG_URL = 'tags/{slug}/'
TAG_SAVE_AS = 'tags/{slug}/index.html'
CATEGORIES_URL = 'categories/'
CATEGORIES_SAVE_AS = 'categories/index.html'
CATEGORY_URL = 'categories/{slug}/'
CATEGORY_SAVE_AS = 'categories/{slug}/index.html'
AUTHORS_URL = 'authors/'
AUTHORS_SAVE_AS = 'authors/index.html'
AUTHOR_URL = 'authors/{slug}/'
AUTHOR_SAVE_AS = 'authors/{slug}/index.html'
# {date:%b} gives short month in words (i.e. 'Apr')
ARTICLE_URL = 'posts/{date:%Y}/{date:%-m}/{date:%-d}/{slug}/'
ARTICLE_SAVE_AS = 'posts/{date:%Y}/{date:%-m}/{date:%-d}/{slug}/index.html'
DAY_ARCHIVE_URL = 'posts/{date:%Y}/{date:%-m}/{date:%-d}/'
DAY_ARCHIVE_SAVE_AS = 'posts/{date:%Y}/{date:%-m}/{date:%-d}/index.html'
MONTH_ARCHIVE_URL = 'posts/{date:%Y}/{date:%-m}/'
MONTH_ARCHIVE_SAVE_AS = 'posts/{date:%Y}/{date:%-m}/index.html'
YEAR_ARCHIVE_URL = 'posts/{date:%Y}/'
YEAR_ARCHIVE_SAVE_AS = 'posts/{date:%Y}/index.html'
ARCHIVES_URL = 'posts/'
ARCHIVES_SAVE_AS = 'posts/index.html'
PRJCT_URL = 'prjct/'
PRJCT_SAVE_AS = 'prjct/index.html'
DIRECT_TEMPLATES = ['index', 'categories', 'authors', 'archives',
'search', 'tags', '404', 'prjct']
PAGINATED_DIRECT_TEMPLATES = ['index', 'archives']
Example 2 — Burst Energy
This is formerly a production site. I’d generate the site locally and then send a zip file containing the site to the hosting provider.
I used invoke to automate the site generation. This automation would also generate graphs (before running Pelican), generate a javascript file needed elsewhere (after running Pelican), and ensure the resulting zip file was in a consistent format.
tasks.py — Invoke configuration file
# Altered fabfile to use with Invoke
from invoke import run, task
import os
import zipfile
from build_js import build_js
from floating_rate_vs_rro_graph import make_graph
# Local path configuration (can be absolute or relative to fabfile)
env_deploy_path = 'output'
env_zipfile = 'burstenergy.zip'
@task
def clean():
if os.path.isdir(env_deploy_path):
run('rm -rf ' + env_deploy_path)
run('mkdir ' + env_deploy_path)
@task
def build():
run('pelican -s pelicanconf.py')
build_js()
make_graph()
@task
def rebuild():
clean()
build()
@task
def regenerate():
run('start pelican -r -s pelicanconf.py')
build_js()
make_graph()
@task
def serve():
run('cd ' + env_deploy_path + ' && start python -m http.server')
@task
def reserve():
build()
build_js()
make_graph()
serve()
@task
def preview():
run('pelican -s publishconf.py')
@task
def build_zip():
zipf = zipfile.ZipFile(env_zipfile, 'w', zipfile.ZIP_DEFLATED)
for root, dirs, files in os.walk(env_deploy_path):
for file in files:
absfile = os.path.join(root, file)
zfile = absfile[len(env_deploy_path)+len(os.sep):] # relative path
zipf.write(absfile, zfile)
zipf.close()
@task
def zip():
clean()
build()
build_zip()
@task
def develop():
clean()
regenerate()
serve()
@task
def build_dieppe():
run('pelican -s pelicanconf-dieppe.py')
@task
def less():
run('lessc theme\\burst-energy\\less\\bootstrap.burst-energy.less > ' +
env_deploy_path + '\\css\\style.css')
# lessc theme\burst-energy\less\bootstrap.burst-energy.less > output\css\style.css
@task
def take_screenshot():
from ghost import Ghost
url = "http://localhost:8000"
gh = Ghost()
# We create a new page
page, page_name = gh.create_page()
# We load the main page of ebay
page_resource = page.open(url, wait_onload_event=True)
# Save the image of the screen
page.capture_to("burst-energy.png")
build_js.py
#!/usr/bin/env python3
# -*- coding: utf-8 -*- #
from __future__ import unicode_literals
'''
This builds the JavaScript files that are used by the MySecure content.
Build the site first, then this will put the JS files in the output directory.
'''
def build_js():
from pelicanconf import OUTPUT_PATH
from bs4 import BeautifulSoup
import os
import re
import codecs
'configuration'
'form file'
FORM_FILE = (os.path.dirname(os.path.realpath(__file__)) + os.sep +
OUTPUT_PATH + os.sep)
FORM_FILE += 'mysecure' + os.sep + 'signup.html'
'output directory'
JS_PATH = (os.path.dirname(os.path.realpath(__file__)) + os.sep +
OUTPUT_PATH + os.sep + 'js')
'Placeholder text'
placeholder = 'PLACEHOLDER'
"test existence of 'form file'"
with open(FORM_FILE, "r") as FORM_FILE_HANDLE:
soup = BeautifulSoup(FORM_FILE_HANDLE, "lxml")
"create `title.js`"
"document title"
with open(JS_PATH + os.sep + 'title.js', "w") as TITLE_JS:
print("var titleblock = ''", file=TITLE_JS)
print("titleblock += '{}'".format(soup.title), file=TITLE_JS)
print("", file=TITLE_JS)
# ToDo: Select the title dynamically,
# based on the file it's called from"
"meta -- viewport"
viewport = soup.find('meta', {'name': 'viewport'})
print("titleblock += '{}'".format(viewport), file=TITLE_JS)
print("", file=TITLE_JS)
print("document.write(titleblock);", file=TITLE_JS)
"create `header.js` and `footerinfo.js`"
on_header = True
my_re2 = re.compile('</?body>')
my_re4 = re.compile(placeholder)
on_header = True
with codecs.open(JS_PATH + os.sep + 'header.js', "w", "utf-8") \
as HEADER_JS:
with codecs.open(JS_PATH + os.sep + 'footerinfo.js', "w", "utf-8") \
as FOOTER_JS:
print("var headerblock = ''", file=HEADER_JS)
print("var footerblock = ''", file=FOOTER_JS)
for line in str(soup.find('body')).split('\n'):
line2 = my_re2.sub('', line)
if my_re4.search(line2):
on_header = False
line2 = ''
if on_header:
print("headerblock += '{}'".format(line2), file=HEADER_JS)
else:
print("footerblock += '{}'".format(line2), file=FOOTER_JS)
print("document.write(headerblock)", file=HEADER_JS)
print("document.write(footerblock)", file=FOOTER_JS)
if __name__ == "__main__":
build_js()
floating_rate_vs_rro_graph.py — to generate graphs
# This generated the graph show the comparision between the RRO and our
# floating rate.
# This graph is displayed on https://www.burstenergy.ca/rates/floating/
Months = ['2014-01', '2014-02', '2014-03', '2014-04', '2014-05', '2014-06',
'2014-07', '2014-08', '2014-09', '2014-10', '2014-11', '2014-12',
'2015-01', '2015-02', '2015-03', '2015-04', '2015-05', '2015-06',
'2015-07', '2015-08', '2015-09', '2015-10', '2015-11', '2015-12',
'2016-01', '2016-02', '2016-03', '2016-04']
# both floating and RRO for Edmonton
RRO = [ 8.689, 7.471, 6.991, 6.986, 8.922, 5.995,
7.198, 8.021, 7.954, 8.737, 7.127, 7.545,
7.302, 6.583, 5.431, 5.832, 4.337, 4.089,
6.140, 5.813, 5.387, 5.498, 5.212, 5.489,
5.304, 4.753, 4.521, 3.65]
Floating = [ 6.149, 11.730, 5.903, 4.438, 7.328, 5.909,
15.801, 6.239, 3.710, 4.011, 5.378, 4.049,
5.001, 4.831, 3.294, 3.282, 7.461, 13.218,
3.692, 4.952, 3.327, 3.412, 3.403, 3.333,
3.441, 2.907, 2.617, 2.503]
# NGX Spot Prices
NGX = [3.8412, 5.4560, 5.1446, 4.4361, 4.4374, 4.3885,
4.2005, 3.8446, 3.8608, 3.7947, 3.7084, 3.6218,
3.0539, 2.7301, 2.7503, 2.5161, 2.5477, 2.5729,
2.5976, 2.7783, 2.7699, 2.6217, 2.4256, 2.3347,
2.3324, 2.0379, 1.5752, 1.3116]
NG_margin = 0.90
def make_graph(Months_Plotted=12):
import os
from pathlib import Path
from statistics import mean
import matplotlib.pyplot as plt
import matplotlib.dates as mdates
from pylab import savefig
from datetime import datetime
# for nicer colours, importing is enough
import seaborn as sns
"""Convert *Months* to numbers"""
for i in range(len(Months)):
year, month = map(int, Months[i].split('-'))
Months[i] = mdates.date2num(datetime(year, month, 1))
"""drop last month on RRO if we have more data than for the floating"""
if len(RRO) > len(Floating):
my_RRO = RRO[:-1]
my_Months = Months[:-1]
else:
my_RRO = RRO
my_Months = Months
my_Floating = Floating
my_NG = [i + NG_margin for i in NGX]
if len(my_Months) > Months_Plotted:
my_Floating = my_Floating[-Months_Plotted:]
my_RRO = my_RRO[-Months_Plotted:]
my_Months = my_Months[-Months_Plotted:]
my_NG = my_NG[-Months_Plotted:]
# averages
average_RRO = [mean(my_RRO) for i in my_Months]
average_Floating = [mean(my_Floating) for i in my_Months]
average_NG = [mean(my_NG) for i in my_Months]
"""Now let's plot!"""
# make the final image 800px wide
fig = plt.figure(dpi=72, figsize=(800/72/1.19, (800*1/2)/72/1.19))
graph = fig.add_subplot(111)
# Plot the two lines
line_RRO = graph.plot(my_Months, my_RRO, sns.xkcd_rgb["pale red"], label="RRO")
line_Burst = graph.plot(my_Months, my_Floating, sns.xkcd_rgb["medium green"], label="Burst Energy")
# x axis -- list the months on the 1st
graph.set_xticks(my_Months)
graph.set_xticklabels([mdates.num2date(date).strftime("%b '%y") for date in my_Months])
# y axis -- min is 0, label
plt.ylim(ymin=0)
plt.ylabel("\u00A2 / kWh, for Edmonton")
# add legend
graph.legend()
# current file location (this script file)
p = Path(os.path.realpath(__file__))
# drop script file name
p = p.parents[0]
# location of where we want to save the graph
p = p / "floating-rate-vs-rro.png"
savefig(str(p), bbox_inches='tight')
# plt.show()
"""Now let's plot (Natural Gas!"""
# make the final image 800px wide
fig = plt.figure(dpi=72, figsize=(800/72/1.19, (800*1/2)/72/1.19))
graph = fig.add_subplot(111)
# Plot the two lines
line_Burst = graph.plot(my_Months, my_NG, sns.xkcd_rgb["medium green"], label="Burst Energy")
# x axis -- list the months on the 1st
graph.set_xticks(my_Months)
graph.set_xticklabels([mdates.num2date(date).strftime("%b '%y") for date in my_Months])
# y axis -- min is 0, label
plt.ylim(ymin=0, ymax=6)
plt.ylabel("$ / GJ, for Alberta")
# add legend
graph.legend()
# current file location (this script file)
p = Path(os.path.realpath(__file__))
# drop script file name
p = p.parents[0]
# location of where we want to save the graph
p = p / "natural-gas.png"
savefig(str(p), bbox_inches='tight')
# plt.show()
def averages(Months_Plotted=12):
import statistics
"""drop last month on RRO if we have more data than for the floating"""
if len(RRO) > len(Floating):
my_RRO = RRO[:-1]
my_Months = Months[:-1]
else:
my_RRO = RRO
my_Months = Months
my_Floating = Floating
my_NG = [i + NG_margin for i in NGX]
if len(my_Months) > Months_Plotted:
my_Floating = my_Floating[-Months_Plotted:]
my_RRO = my_RRO[-Months_Plotted:]
my_Months = my_Months[-Months_Plotted:]
my_NG = my_NG[-Months_Plotted:]
ave_RRO = statistics.mean(my_RRO)
ave_Floating = statistics.mean(my_Floating)
ave_NG = statistics.mean(my_NG)
print("For the last {} months, the average is:".format(Months_Plotted))
print("{}For the RRO, {:.3f} ¢/kWh".format(" ", ave_RRO))
print("{}For the Floating rate, {:.3f} ¢/kWh".format(" ", ave_Floating))
print("{}For natural gas, ${:.2f} /GJ".format(" ", ave_NG))
if __name__ == "__main__":
make_graph(12)
averages(6)
averages(12)
pelicanconf.py — Pelican Configuration
#!/usr/bin/env python
# -*- coding: utf-8 -*- #
from __future__ import unicode_literals
AUTHOR = 'Burst Energy'
SITENAME = 'Burst Energy'
SITEURL = 'https://www.burstenergy.ca' # used by the sitemap generator
WEB_URL = '' # "SITEURL" as used by the templates (so for the published web pages)
CANONICAL_SITEURL = SITEURL
PATH = 'content'
OUTPUT_PATH = 'output'
TIMEZONE = 'America/Edmonton'
DEFAULT_LANG = u'en'
DEFAULT_DATE = 'fs'
# Feed generation is usually not desired when developing
FEED_ALL_ATOM = None
CATEGORY_FEED_ATOM = None
TRANSLATION_FEED_ATOM = None
AUTHOR_FEED_ATOM = None
AUTHOR_FEED_RSS = None
# Theme
THEME = 'theme/burst-energy'
CUSTOM_CSS = 'css/burst-energy.css'
BANNER_SUBTITLE = 'Simple Electricity'
HIDE_SIDEBAR = True
BANNER = BANNER_ALL_PAGES = False
TYPOGRIFY = True
COPY_DATE = '2014-15'
BOOTSTRAP_NAVBAR_INVERSE = False
SITELOGO = WEB_URL + 'images/burst-energy-logo-sol-white-230.png'
# SITELOGO_WIDTH = '110px'
SITELOGO_HEIGHT = '25px'
FOOTER_LOGO = WEB_URL + 'images/burst-energy-logo-sol-230.png'
FOOTER_LOGO_WIDTH = '220px'
HIDE_SITENAME = True
BOOTSTRAP_THEME = 'burst-energy'
THEME_COLOR = "#2C3E50"
FAVICON = WEB_URL + 'images/favicon.png'
FAVICON_IE = WEB_URL + 'favicon.ico'
TOUCHICON = WEB_URL + 'images/apple-touch-icon.png'
# PYGMENTS_STYLE =
GOOGLE_ANALYTICS_UNIVERSAL = 'UA-49197109-1'
GOOGLE_ANALYTICS_UNIVERSAL_PROPERTY = 'burstenergy.ca'
DISPLAY_PAGES_ON_MENU = False
DISPLAY_CATEGORIES_ON_MENU = False
DISPLAY_ARCHIVES_ON_MENU = False
MENU_ITEMS_ONE = (('News', WEB_URL + '/news/', None),
('Our Rates', WEB_URL + '/rates/', None),
('Electricity 101', WEB_URL + '/electricity-101/', None),
)
MENU_ITEMS_TWO = (('Sign Up', WEB_URL + '/mysecure/signup.html', 'glyphicon glyphicon-ok-circle'),
('My Account', WEB_URL + '/mysecure/portal.html', 'fa fa-sign-in'),
)
INDEX_SAVE_AS = "news/index.html"
DISPLAY_ARTICLE_INFO_ON_INDEX = True
# Link Structure
PAGE_URL = '{slug}/'
PAGE_SAVE_AS = '{slug}/index.html'
ARTICLE_URL = 'news/{date:%Y}/{slug}/'
ARTICLE_SAVE_AS = 'news/{date:%Y}/{slug}/index.html'
YEAR_ARCHIVE_SAVE_AS = 'news/{date:%Y}/index.html'
CATEGORIES_SAVE_AS = 'category/index.html'
AUTHORS_SAVE_AS = 'author/index.html'
STATIC_PATHS = ['images',
'js',
'favicon.ico',
'browserconfig.xml',
'robots.txt', ]
# Contact Info
CONTACT_WEB_EMAIL = "webteam@burstenergy.ca"
CONTACT_PHONE = "(780) 665-9918"
C_RETAIL_FAX = "(403) 265-7290"
C_CORPORATE_EMAIL = "william@burstenergy.ca"
FOOTER_ADDRESS = "Suite 200, 1316 9<sup>th</sup> Avenue SE<br />Calgary, Alberta T2G 0T3"
SOCIAL = (('facebook', 'https://www.facebook.com/BurstEnergyCA'),
('twitter', 'http://twitter.com/BurstEnergy'),
)
FOOTER_LINKS = (('About Us', WEB_URL + '/about/'),
('FAQ', WEB_URL + '/faq/'),
('Glossary', WEB_URL + '/gloss/'),
('Quick Links', WEB_URL + '/quicklinks/'),
('Privacy', WEB_URL + '/privacy/'),
('Legal', WEB_URL + '/legal/'),
)
# Plugins
PLUGIN_PATHS = ['S:\\Documents\\GitHub\\pelican-plugins', 'C:\\Users\\User\\Documents\\GitHub\\pelican-plugins']
PLUGINS = ['pelican_alias',
'assets',
'extended_sitemap',
'neighbors']
USE_ASSETS = True
ASSETS_CSS = True
ASSETS_JS = False
SITEMAP = {
"format": "xml",
}
EXTENDED_SITEMAP_PLUGIN = {
'priorities': {
'index': 1.0,
'articles': 0.5,
'pages': 0.8,
'others': 0.4
},
'changefrequencies': {
'index': 'daily',
'articles': 'weekly',
'pages': 'weekly',
'others': 'monthly',
}
}
DEFAULT_PAGINATION = 10
# Uncomment following line if you want document-relative URLs when developing
# RELATIVE_URLS = True
# Nav bar links are set expliciately above
# pages set to hidden don't show up in sitemap
# sitemap also uses the 'date' as last modified
Minchin.ca
This is my personal website at http://minchin.ca. I’ve edited Bootstrap
extensively (colours, fonts, vertical menu). The theme has since been posted to
PyPI as seafoam and is installable via
pip. The code for the
site, and the
site ifself, are both hosted on GitHub Pages.
pelicanconf.py — Pelican Configuration
#!/usr/bin/env python
# -*- coding: utf-8 -*- #
from __future__ import unicode_literals
AUTHOR = u'Wm. Minchin'
SITENAME = u'Minchin.ca'
SITEURL = 'http://minchin.ca'
SITE_ROOT_URL = SITEURL
TIMEZONE = 'America/Edmonton'
DEFAULT_LANG = u'en'
# Uncomment following line if you want document-relative URLs when developing
RELATIVE_URLS = True
# Feed generation is usually not desired when developing
FEED_ALL_ATOM = None
CATEGORY_FEED_ATOM = None
TRANSLATION_FEED_ATOM = None
DEFAULT_PAGINATION = False
# static paths will be copied under the same name
STATIC_PATHS = ['images',
'..\extras',
'css',
'projects\design',
'..\.gitattributes',
'..\.gitignore',
'..\README.txt', ]
# A list of files to copy from the source to the destination
EXTRA_PATH_METADATA = {
'../.gitattributes': {'path': '.gitattributes'},
'../.gitignore': {'path': '.gitignore'},
'../README.txt': {'path': 'README.txt'},
# CNAME file tells GitHub Pages to display this site at minchin.ca
'../extras/CNAME': {'path': 'CNAME'},
'../extras/minchin.ico': {'path': 'favicon.ico'},
'../extras/MTS_1v1.xlsm': {'path': 'MTS_1v1.xlsm'},
'../extras/TRB_Minchin.ca.XSL': {'path': 'TRB_Minchin.ca.XSL'},
'../extras/googlecbc66a9bfde8606b.html': {'path': 'googlecbc66a9bfde8606b.html'},
'../extras/.nojekyll': {'path': '.nojekyll'},
# prism is used by the blog for code highlighting
'../extras/prism.js': {'path': 'js/prism.js'},
'../extras/prism.css': {'path': 'css/prism.css'},
}
# Custom settings
MARKUP = (('rst',
'md',
'markdown',
'mkd',
'mdown',)) # don't include htm and html files
READERS = {'html': None,
'htm': None}
PATH = 'content'
OUTPUT_PATH = '../minchinweb.github.io-master/'
# Add Blog to sidebar
MENUITEMS = (('Blog', 'http://blog.minchin.ca/', 'fa fa-pencil'), )
DISPLAY_PAGES_ON_MENU = True
# disable Tags, etc
TAGS_SAVE_AS = ''
TAG_SAVE_AS = ''
CATEGORY_URL = ''
CATEGORY_SAVE_AS = ''
CATEGORIES_URL = ''
CATEGORIES_SAVE_AS = ''
ARTICLE_URL = ''
ARTICLE_SAVE_AS = ''
AUTHORS_URL = ''
AUTHORS_SAVE_AS = ''
ARCHIVES_URL = ''
ARCHIVES_SAVE_AS = ''
PAGE_URL = "{slug}/"
PAGE_SAVE_AS = "{slug}/index.html"
# Theme Related
TYPOGRIFY = True
THEME = 'themes/pelican-minchin-ca'
SITELOGO = 'images/MinchindotCA-200.png'
SITELOGO_SIZE = '100%'
PYGMENTS_STYLE = 'friendly'
DISPLAY_BREADCRUMBS = True
FAVICON = 'favicon.ico'
BOOTSTRAP_THEME = 'minchin-ca'
USE_OPEN_GRAPH = True
CUSTOM_CSS = 'css/minchin-ca.css'
DOCUTIL_CSS = False
GOOGLE_ANALYTICS_UNIVERSAL = 'UA-384291-3'
GOOGLE_ANALYTICS_UNIVERSAL_PROPERTY = 'minchin.ca'
# Plugins
PLUGIN_PATHS = ['../pelican-plugins', ]
PLUGINS = ['assets', ]
ASSET_CSS = False
ASSET_JS = False
SITEMAP = {
"format": "xml",
}
# # Make things disappear
DISPLAY_CATEGORIES_ON_MENU = False
HIDE_SITENAME = True
HIDE_SIDEBAR = True
FEED_ALL_ATOM = False
FEED_ALL_RSS = False
GITHUB_USER = False
ADDTHIS_PROFILE = False
DISQUS_SITENAME = False
PDF_PROCESSOR = False
Minchin Genealogy
I host a copy of my genealogy on my personal website. The generate site contains over 11,000 pages (and so demonstrates that Pelican can handle very large sites). This site uses the same theme as Minchin.ca. I’ve used automation (in this case, a Python script) to automate source data generation and final site upload. This is hosted on GitHub pages as a project page. This site is set up to allow comments via email.
gen_upload.py — Build Automation Script
#!/usr/bin/python
# -*- coding: utf-8 -*-
'''Genealogy Uploader
v.3.2.3 - WM - January 7, 2016
This script serves to semi-automate the building and uploading of my
genealogy website. It is intended to be semi-interactive and run from the
command line.'''
import codecs
from datetime import date, datetime
import fileinput
import multiprocessing as mp
import os
from pathlib import Path
import re
import sys
import textwrap
import uuid
import webbrowser
import zipfile
from bs4 import BeautifulSoup
import colorama
from colorama import Fore, Style
from invoke import run, task
from joblib import Parallel, delayed
import requests
import winshell
import minchin.text
__version__ = '3.2.3'
colorama.init()
COPYRIGHT_START_YEAR = 1987
ADAM_LINK = "http://gigatrees.com"
ADAM_FOOTER = "<p><strong>Are we related?</strong> Are you a long lost cousin? Spotted an error here? This website remains a work-in-progress and I would love to hear from you. Drop me a line at minchinweb [at] gmail [dot] com.</p>"
INDENT = " "*4
GITHUB_FOLDER = Path("S:\Documents\GitHub\genealogy-gh-pages")
PHOTO_FOLER = Path("S:\Documents\Genealogy")
DOWNLOAD_FOLDER = Path("S:\Downloads\Chrome")
URL_ROOT = "http://minchin.ca/genealogy"
REPO_URL = "https://github.com/MinchinWeb/genealogy.git"
ADAM_PREFIX = 'william-minchin-gigatree-offline-'
TODAY_STR = '' + str(date.today().year)[2:] + str.zfill(str(date.today().month), 2) + str.zfill(str(date.today().day), 2)
GEDCOM_EXPECTED = 'William ' + TODAY_STR + '.ged'
USER_FOLDER = Path(os.path.expanduser('~'))
MY_GEDCOM = USER_FOLDER / 'Desktop' / GEDCOM_EXPECTED
start_time = datetime.now()
step_no = 0 # step counter
# folder where the script is saved
HERE_FOLDER = Path(os.path.dirname(os.path.realpath(__file__)))
WORKING_FOLDER = HERE_FOLDER # current working directory
CONTENT_FOLDER = HERE_FOLDER / 'content' / 'pages'
adam_zip = '' # set later
tracking_filename = '' # set later
def addimage(image):
'''Take the file listed in image, finds in my genealogy photo directory, and
adds it to the GitHub folder.'''
'''TO-DO: implement this!!'''
pass
# multiple replacement
# from http://stackoverflow.com/questions/6116978/python-replace-multiple-strings
#
# Usage:
# >>> replacements = (u"café", u"tea"), (u"tea", u"café"), (u"like", u"love")
# >>> print multiple_replace(u"Do you like café? No, I prefer tea.", *replacements)
# Do you love tea? No, I prefer café.
def multiple_replacer(*key_values):
replace_dict = dict(key_values)
replacement_function = lambda match: replace_dict[match.group(0)]
pattern = re.compile("|".join([re.escape(k) for k, v in key_values]), re.M | re.I)
return lambda string: pattern.sub(replacement_function, string)
def multiple_replace(string, *key_values):
return multiple_replacer(*key_values)(string)
def get_adam_version():
soup_file = open(str(CONTENT_FOLDER / 'names.html'), 'r')
soup = BeautifulSoup(soup_file, "lxml")
soup_file.close()
return soup.find(True, "gt-version").get_text().encode('utf-8') # 'Built by Adam 1.35.0.0' or the like
@task
def export_gedcom():
'''Export from RootsMagic.'''
global step_no
global start_time
step_no += 1
minchin.text.clock_on_right(str(step_no).rjust(2) + ". Export from RootsMagic.")
print("{}call the file {}{}{} and save it to the desktop".format(INDENT*2, Style.BRIGHT, GEDCOM_EXPECTED, Style.RESET_ALL))
print("{}do not include LDS information".format(INDENT*2))
print("{}no need to privatize individuals (at this step)".format(INDENT*2))
if not minchin.text.query_yes_quit("{}Next?".format(INDENT), default="yes"):
sys.exit()
try:
start_time = datetime.fromtimestamp(os.stat(MY_GEDCOM).st_ctime)
except:
print("{}Your file doesn't seem to exist. Exiting...".format(INDENT))
@task
def clean_gedcom():
'''Cleaning up GEDCOM.'''
global step_no
step_no += 1
minchin.text.clock_on_right(str(step_no).rjust(2) + ". Cleaning up GEDCOM.")
# replace image paths
gedcom_file = open(str(MY_GEDCOM), 'r', encoding='utf-8') # add failsafe is the fail doesn't exist yet or is still being written to
subject = gedcom_file.read()
gedcom_file.close()
pattern = re.compile(r'S:\\Documents\\Genealogy\\([0-9]+[\.[a-z]+]*\.? )*', re.IGNORECASE) # path start
result = pattern.sub('images/', subject)
pattern2 = re.compile(r'(images.*)\\') # reverse slashes in rest of path
result2 = pattern2.sub(r'\1/', result)
result3 = pattern2.sub(r'\1/', result2)
f_out = open(str(MY_GEDCOM), 'w', encoding='utf-8')
f_out.write(result3)
f_out.close()
@task
def upload_gedcom():
'''Upload GEDCOM to Gigatree.'''
global step_no
step_no += 1
minchin.text.clock_on_right(str(step_no).rjust(2) + ". The file is now ready to upload to Gigatrees.")
webbrowser.open("http://gigatrees.com/toolbox/gigatree", new=2)
print("{}log-in (using Facebook)".format(INDENT*2))
print("{}now click 'generate report'".format(INDENT*2))
# check to see if we're logged in
# log in, if needed
# discard old GEDCOM
# upload new GEDCOM
# run generator
# download new output
@task
def check_images():
'''Check which images have already been uploaded.'''
global step_no
step_no += 1
minchin.text.clock_on_right(str(step_no).rjust(2) + ". Checking images.")
gedcom_file = open(str(MY_GEDCOM), 'r', encoding='utf-8')
subject = gedcom_file.read()
gedcom_file.close()
missing_matches = []
all_matches = []
matches = 0
wrapper = textwrap.TextWrapper(width=79, initial_indent=INDENT, subsequent_indent=INDENT*2)
pattern_bad = re.compile("missing ")
for match in re.findall(r'(images/.+\.(jpg|jpeg|png|gif|pdf))', subject, re.IGNORECASE):
all_matches.append(match)
all_matches = sorted(set(all_matches)) # remove duplicates and sort
for match in all_matches:
r = requests.head(URL_ROOT + "/" + str(match[0]), allow_redirects=True)
if not r.status_code == requests.codes.ok:
mytext = wrapper.fill("missing {} -> {}".format(str(r.status_code), match[0]))
print(pattern_bad.sub(Fore.RED + Style.BRIGHT + "missing " + Style.RESET_ALL, mytext))
missing_matches.append(match[0])
else:
matches += 1
if len(missing_matches) == 0:
print("{}{} images matching. No missing images.".format(INDENT, str(matches)))
else:
print("{}{} images matching.".format(INDENT, str(matches)))
q_add_images = minchin.text.query_yes_no_all("{}{} missing images. Add them?".format(INDENT, str(len(missing_matches))), default="no")
if q_add_images == 2: # all
for image in missing_matches:
addimage(image)
elif q_add_images == 1: # yes
for image in missing_matches:
if minchin.text.querry_yes_no("{}Add {}?".format(INDENT*2, image), default="yes"):
addimage(image)
# TO-DO: implement this!
else:
pass
else: # no
pass
# write missing images to a file
f = open('missing-images.txt', 'w', encoding='utf-8')
f.write("Genealogy Uploader, v.{}\n".format(str(__version__)))
f.write('{}\n\n'.format(MY_GEDCOM))
for missing in missing_matches:
f.write('{}\n'.format(missing))
f.close()
@task
def delete_old_output():
'''Delete old Pelican output.'''
global step_no
step_no += 1
minchin.text.clock_on_right(str(step_no).rjust(2) + ". Deleting old Pelican output.")
to_delete = []
html_files = 0
os.chdir(str(GITHUB_FOLDER))
all_files = os.listdir(str(GITHUB_FOLDER))
for filename in all_files:
if filename == ('.git'):
pass # don't drop the GIT repo
elif filename == ('images'):
pass # don't drop the image folder
elif filename.endswith('.html'):
html_files += 1
else:
to_delete.append(filename)
counter = 0
# delete HTML files
run('del *.html -y')
bar = minchin.text.progressbar(maximum=len(to_delete) + html_files)
counter = html_files
bar.update(counter)
# delete everything else
for my_file in to_delete:
winshell.delete_file(my_file, no_confirm=True, allow_undo=False, silent=True)
counter += 1
bar.update(counter)
print("\n{}{} files deleted.".format(INDENT*2, str(len(to_delete) + html_files)))
@task
def delete_old_adam():
'''Delete old Gigatrees output.'''
global step_no
step_no += 1
minchin.text.clock_on_right(str(step_no).rjust(2) + ". Deleting old Gigatree output.")
os.chdir(str(CONTENT_FOLDER))
run('del *.* /q')
@task
def get_new_adam():
'''Get new Gigatree output.'''
# TO-DO: allow override of 'start time'
global step_no
global adam_zip
step_no += 1
minchin.text.clock_on_right(str(step_no).rjust(2) + ". Get new Gigatree output.")
os.chdir(str(DOWNLOAD_FOLDER))
gedcom_time = datetime.fromtimestamp(os.stat(str(MY_GEDCOM)).st_ctime)
count_loops = 0
while True:
all_files = os.listdir(str(DOWNLOAD_FOLDER))
for filename in all_files:
if filename.startswith(ADAM_PREFIX) and filename.endswith(".zip"):
if datetime.fromtimestamp(os.stat(filename).st_ctime) > gedcom_time:
adam_zip = filename
if adam_zip != '' and os.stat(adam_zip).st_size > 1000:
break
count_loops += 1
if count_loops > 60:
if minchin.text.query_yes_quit("{}We've waited 30 minutes. Keep waiting?".format(INDENT), default="yes") is False:
sys.exit()
else:
count_loops = 0
else:
minchin.text.wait(30)
winshell.copy_file(adam_zip, str(CONTENT_FOLDER))
def step_unzip():
# Test 1: 6:48.948 for 9,999 files
# Test 2: 2:05.188204 for 11,1698 files
global step_no
start_time_local = datetime.now()
step_no += 1
minchin.text.clock_on_right(str(step_no).rjust(2) + ". Unzip new Gigatree output (Zipfile).")
os.chdir(str(CONTENT_FOLDER))
zf = zipfile.ZipFile(adam_zip)
zf.extractall()
zf.close()
print(INDENT, datetime.now() - start_time_local)
def step_unzip_faster():
# see http://dmarkey.com/wordpress/2011/10/15/python-zipfile-speedup-tips/
# Test 1: 4:44.459 for 9,999 files
# this doesn't appear to work on Python 3.5.1, says it's not a zip file
global step_no
start_time_local = datetime.now()
step_no += 1
minchin.text.clock_on_right(str(step_no).rjust(2) + ". Unzip new Gigatree output (Zipfile faster).")
os.chdir(str(CONTENT_FOLDER))
zf = zipfile.ZipFile(open(adam_zip, 'r'))
zf.extractall()
zf.close()
print(INDENT, datetime.now() - start_time_local)
def step_unzip_czip():
# Test 1: 4:46.109 for 9,999 files
# Test 2: xx for 11,1698 files
global step_no
start_time_local = datetime.now()
step_no += 1
minchin.text.clock_on_right(str(step_no).rjust(2) + ". Unzip new Gigatree output (czip).")
os.chdir(str(CONTENT_FOLDER))
zf = czipfile.ZipFile(adam_zip)
zf.extractall()
zf.close()
print(INDENT, datetime.now() - start_time_local)
@task
def step_unzip_7zip():
# Test 1: 5:09.974 for 9,999 files
# Test 2: 1:43.229726 for 11,1698 files
global step_no
start_time_local = datetime.now()
step_no += 1
minchin.text.clock_on_right(str(step_no).rjust(2) + ". Unzip new Gigatree output (7-zip).")
os.chdir(str(CONTENT_FOLDER))
run('"C:\\Program Files\\7-Zip\\7z.exe" e {} > nul'.format(adam_zip))
print(INDENT, datetime.now() - start_time_local)
def step_unzip_infozip():
# Test 2: 1:51.550671 for 11,1698 files
global step_no
start_time_local = datetime.now()
step_no += 1
minchin.text.clock_on_right(str(step_no).rjust(2) + ". Unzip new Gigatree output (unzip.exe).")
os.chdir(str(CONTENT_FOLDER))
run('C:\\bin\\unzip.exe {} > nul'.format(adam_zip))
print(INDENT, datetime.now() - start_time_local)
@task
def unzip_adam():
'''Unzip new Adam output.'''
try:
step_unzip_7zip()
except:
step_unzip()
@task
def php_to_html():
'''Change any .php files to .html.'''
global step_no
step_no += 1
minchin.text.clock_on_right(str(step_no).rjust(2) + ". Rename all .php files.")
os.chdir(str(CONTENT_FOLDER))
run('rename *.php *.html')
@task
def copy_js():
'''Copy Gigatree .js files.'''
global step_no
step_no += 1
minchin.text.clock_on_right(str(step_no).rjust(2) + ". Copy Gigatree .js files.")
# files are copied from the base CONTENT_FOLDER (where they are put by unzipping
# the adam.zip) to the CONTENT_FOLDER / js (where Pelican will find them)
js_files = ('tab-list-handler.js',
'tooltip-handler.js',
'graph-handler.js',
'gigatrees-map-min.js', )
for my_file in js_files:
try:
winshell.delete_file(str(CONTENT_FOLDER / 'js' / my_file), no_confirm=True, allow_undo=False, silent=True)
except:
pass
winshell.copy_file(str(CONTENT_FOLDER / my_file), str(CONTENT_FOLDER / 'js' / my_file), no_confirm=True)
# not needed; the elements of the 'gigatrees.css' needed have been folded
# directly into the theme LESS files
@task
def copy_css():
'''Copy Gigatree .css files.'''
global step_no
step_no += 1
minchin.text.clock_on_right(str(step_no).rjust(2) + ". Copy Gigatree .css files.")
os.chdir(str(CONTENT_FOLDER))
css_files = ('gigatrees.css', )
for my_file in css_files:
try:
winshell.delete_file("../css/" + my_file, no_confirm=True, allow_undo=False, silent=True)
except:
pass
winshell.copy_file(my_file, "../css/" + my_file, no_confirm=True)
@task
def copy_img():
'''Copy Gigatree image files.'''
global step_no
step_no += 1
minchin.text.clock_on_right(str(step_no).rjust(2) + ". Copy Gigatree image files.")
# files are copied from the base CONTENT_FOLDER (where they are put by unzipping
# the adam.zip) to the CONTENT_FOLDER / img (where Pelican will find them)
img_files = ('arrowd.png',
'arrowl.png',
'arrowr.png',
'arrowu.png',
'bg-black.png',
'bg-pattern.png',
'mapicon_f.png',
'mapicon_m.png',
'mapicon_u.png',
'mapmarker1.png',
'mapmarker2.png',
'mapmarker3.png',
'mapmarker4.png',
'mapmarker5.png',
'avatar.jpg',
'image.jpg',
'pdf.jpg', )
for my_file in img_files:
try:
winshell.delete_file(str(CONTENT_FOLDER / 'img' / my_file), no_confirm=True, allow_undo=False, silent=True)
except:
pass
winshell.copy_file(str(CONTENT_FOLDER / my_file), str(CONTENT_FOLDER / 'img' / my_file), no_confirm=True)
@task
def replace_index():
'''Copy over index.md, 404.md.'''
global step_no
step_no += 1
minchin.text.clock_on_right(str(step_no).rjust(2) + ". Copy over index.md, 404.md.")
os.chdir(str(CONTENT_FOLDER))
for my_file in ("index.md", "index.html", "404.md"):
try:
winshell.delete_file(my_file, no_confirm=True, allow_undo=False, silent=True)
except:
pass
for my_file in ("index.md", "404.md"):
winshell.copy_file("../../_unchanging_pages/{}".format(my_file), my_file, no_confirm=True)
@task
def set_pelican_variables():
'''Sets a couple of variables that Pelican uses while generating the site.'''
global step_no
step_no += 1
minchin.text.clock_on_right(str(step_no).rjust(2) + ". Setting up Pelican.")
adam_version_text = get_adam_version() # 'Built by Adam 1.35.0.0 ' or the like
adam_version_text = adam_version_text.decode('utf-8').strip()
date_in_text = date.today().strftime("%B %d, %Y").replace(' 0', ' ') # 'January 7, 2014' or the like
year_range = "{}-{}".format(COPYRIGHT_START_YEAR, datetime.now().year)
print('{}{} - {}'.format(INDENT, adam_version_text, date_in_text))
f = open(str(WORKING_FOLDER / 'adamconf.py'), 'w')
f.write('# Genealogy Uploader, v.{}\n'.format(str(__version__)))
f.write('# {}\n\n'.format(str(MY_GEDCOM)))
f.write('ADAM = True\n')
f.write('ADAM_VERSION = "{}"\n'.format(adam_version_text))
f.write('ADAM_UPDATED = "{}"\n'.format(date_in_text))
f.write('ADAM_COPY_DATE = "{}"\n'.format(year_range))
f.write('ADAM_LINK = "{}"\n'.format(ADAM_LINK))
f.write('ADAM_FOOTER = "{}"\n'.format(ADAM_FOOTER))
f.write('ADAM_PUBLISH = True\n')
f.close()
@task
def replace_emails():
'''Hide emails in Sources.'''
global step_no
step_no += 1
minchin.text.clock_on_right(str(step_no).rjust(2) + ". Hiding Emails.")
# replace and hide emails; but some of these are over lines breaks,
# so we'll have to search and replace through the output
# We are actually only considering 'Sources', as that's where
# all the emails seem to be...
replacements = ("someone@hotmail.com", '[email redacted]'), \
("someone@gmail.com", '[email redacted]'),
os.chdir(str(CONTENT_FOLDER))
all_files = os.listdir(str(CONTENT_FOLDER))
all_html_files = []
for my_file in all_files:
#if my_file.endswith(".html"):
if my_file.startswith('sources-'):
all_html_files.append(my_file)
counter = 0
bar = minchin.text.progressbar(maximum=len(all_html_files))
# inline search and replace
for my_file in all_html_files:
for line in fileinput.input(my_file, inplace=1):
print(multiple_replace(line, *replacements))
counter += 1
bar.update(counter)
print() # clear progress bar
def html_fixes(my_file):
'''
Applies the various updates and changes I want done to the raw Gigatrees
HTML.
Assumes 'my_file' is in the CONTENT_FOLDER.
Assumes 'my_file' is a string.
'''
with codecs.open(str(CONTENT_FOLDER / my_file), 'r', 'utf-8') as html_doc:
my_html = html_doc.read()
soup = BeautifulSoup(my_html, "lxml")
# change page title
title_tag = soup.html.head.title
for tag in soup(id="gt-page-title", limit=1):
title_tag.string.replace_with(tag.string.strip())
tag.decompose()
# dump all the meta tags in the head section
for tag in soup("meta"):
tag.decompose()
# Remove links to CDN stuff I serve locally
js_served_locally = ('jquery.min.js',
'jquery-ui.min.js',
'bootstrap.min.js',
'globalize.min.js',
'dx.chartjs.js')
for tag in soup("script"):
try:
link = tag["src"]
if link.endswith(js_served_locally):
tag.decompose()
except:
pass
# fix pdf paths?
# other stuff
for tag in soup(id="gt-page-title"):
tag.decompose()
for tag in soup(class_="gt-version", limit=1):
tag.decompose()
# at meta tags, used for the breadcrumbs in the link.
# they need to be in the <head> section, in the form
#
# <head>
# <!-- other stuff... -->
# <meta name="at" content="Locations" />
# <meta name="at_link" content="places.html" /> <!-- this is added to SITEURL -->
# </head>
new_tags = False
if my_file.startswith("names-"):
new_tag_1 = soup.new_tag("meta", content="Surnames")
new_tag_2 = soup.new_tag("meta", content="names.html")
new_tags = True
elif my_file.startswith("places-"):
new_tag_1 = soup.new_tag("meta", content="Locations")
new_tag_2 = soup.new_tag("meta", content="places.html")
new_tags = True
elif my_file.startswith("sources-"):
new_tag_1 = soup.new_tag("meta", content="Sources")
new_tag_2 = soup.new_tag("meta", content="sources.html")
new_tags = True
elif my_file.startswith("timeline") and my_file != "timeline.html":
new_tag_1 = soup.new_tag("meta", content="Timelines")
new_tag_2 = soup.new_tag("meta", content="timeline.html")
new_tags = True
if new_tags:
new_tag_1.attrs['name'] = 'at'
new_tag_2.attrs['name'] = 'at_link'
soup.html.head.append(new_tag_1)
soup.html.head.append(new_tag_2)
# write fixed version of file to disk
with codecs.open(str(CONTENT_FOLDER / my_file), 'w', 'utf-8') as html_doc:
html_doc.write(str(soup))
#html_doc.write(soup.prettify())
def html_fixes_2(my_file, my_bar, my_counter):
'''
Applies the HTML changes and then updates the counter.
Assumes 'my_bar' is of type minchin.text.progressbar
Assumes 'my_counter' is of type multiprocessing.Value
'''
html_fixes(my_file)
# get the lock so that different threads can't update it at the same time
with my_counter.get_lock():
my_counter.value += 1
my_bar.update(my_counter.value)
'''
For 11,146 files (2 core, 4 thread machine, program run time):
- no html cleaning (so just overhead):
13:50 (partial delete, 7-Zip), 24:52, 21:56, 25:59 (Zipfile)
- single thread: 18:49.190113
- multi-threaded (n_jobs=9): 4:59.657586
'''
@task
def clean_adam_html_single_thread():
'''Remove nasty and extra HTML.'''
global step_no
start_time_local = datetime.now()
step_no += 1
minchin.text.clock_on_right(str(step_no).rjust(2) + ". Remove nasty and extra HTML (single threaded).")
#os.chdir(str(CONTENT_FOLDER))
all_files = os.listdir(str(CONTENT_FOLDER))
all_html_files = []
for my_file in all_files:
if my_file.endswith(".html"):
all_html_files.append(my_file)
# this gives us a C-type integer, useful for accessing from multiple threads
counter = mp.Value('i', 0)
bar = minchin.text.progressbar(maximum=len(all_html_files))
bar.update(counter.value)
for my_file in all_html_files:
html_fixes_2(my_file, bar, counter)
print() # clear progress bar
print(INDENT, datetime.now() - start_time_local)
@task
def clean_adam_html_multithreaded(my_n_jobs=None):
'''Remove nasty and extra HTML (multi-threaded).'''
'''
Benchmarks
n_jobs time
9 6:20
6 6:18 (machine has 6 cores)
4 7:16
'''
global step_no
#start_time_local = datetime.now()
step_no += 1
minchin.text.clock_on_right(str(step_no).rjust(2) + ". Remove nasty and extra HTML (multi-threaded).")
all_files = os.listdir(str(CONTENT_FOLDER))
all_html_files = []
for my_file in all_files:
if my_file.endswith(".html"):
all_html_files.append(my_file)
if my_n_jobs is None:
my_n_jobs = int(os.cpu_count())
Parallel(n_jobs=my_n_jobs, verbose=5)(delayed(html_fixes)(my_file) for my_file in all_html_files)
#print(INDENT, datetime.now() - start_time_local)
@task
def pelican():
'''Run Pelican.'''
global step_no
step_no += 1
minchin.text.clock_on_right(str(step_no).rjust(2) + ". Run Pelican (site generator).")
os.chdir(str(WORKING_FOLDER))
run('pelican -s publishconf.py')
@task
def pelican_local():
'''Run Pelican (in local, developmental mode).'''
global step_no
step_no += 1
minchin.text.clock_on_right(str(step_no).rjust(2) + ". Run Pelican (site generator) in local mode.")
os.chdir(str(WORKING_FOLDER))
run('pelican -s pelicanconf.py')
@task
def create_tracking():
'''Create deploy tracking file.'''
global step_no
global tracking_filename
step_no += 1
minchin.text.clock_on_right(str(step_no).rjust(2) + ". Create deploy tracking file.")
# create a 'random' number using UUID
# note that the last set of digits will correspond to the workstation
myUUID = str(uuid.uuid1())
tracking_filename = myUUID + ".txt"
target = open(str(GITHUB_FOLDER / tracking_filename), 'w')
target.write(myUUID + "\n")
target.write("Adam upload by Python script.\n")
target.write(GEDCOM_EXPECTED + "\n")
target.close()
@task
def git():
'''Git commit and push.'''
global step_no
step_no += 1
minchin.text.clock_on_right(str(step_no).rjust(2) + ". Git -> commit and push.")
commit_msg = "Gigatrees generated upload from {}".format(GEDCOM_EXPECTED)
os.chdir(str(GITHUB_FOLDER))
minchin.text.clock_on_right('{}{}> git add -A{}'.format(INDENT, Fore.YELLOW, Style.RESET_ALL))
r1 = run('git add -A', hide=True)
print(r1.stderr)
minchin.text.clock_on_right('{}{}> git commit -m "{}"{}'.format(INDENT, Fore.YELLOW, commit_msg, Style.RESET_ALL))
r2 = run('git commit -m Gigatrees_upload', hide=True)
print(r2.stderr)
minchin.text.clock_on_right('{}{}> git push origin{}'.format(INDENT, Fore.YELLOW, Style.RESET_ALL))
r3 = run('git push origin', hide=True)
print(r3.stdout)
print(r3.stderr)
@task
def live():
'''Tell us when we're live.'''
# TO-DO: find tracking file based on creation/modified date
global step_no
step_no += 1
minchin.text.clock_on_right(str(step_no).rjust(2) + ". Wait to go live.")
if tracking_filename is None:
print('{}No tracking file set.'.format(INDENT))
else:
while True:
r = requests.head(URL_ROOT + "/" + tracking_filename, allow_redirects=True)
if r.status_code == requests.codes.ok:
break
else:
minchin.text.wait(180)
@task
def all_steps():
'''Everything!'''
minchin.text.title("Genealogy Uploader, v.{}".format(str(__version__)))
print()
export_gedcom() # works 151230
clean_gedcom() # works
upload_gedcom() # works
#check_images() # works
delete_old_output() # works
delete_old_adam() # works ~2 min
get_new_adam() #
unzip_adam() # pretty sure works ~5 min
#php_to_html() # works, brakes if there are no PHP files
copy_js() # works
#copy_css()
copy_img()
replace_index() # works
set_pelican_variables() # works
clean_adam_html_multithreaded()
replace_emails() # doesn't crash
create_tracking() # works ~10 sec
pelican() # works (assuming Pelican works)
git() #
live() #
minchin.text.clock_on_right(Fore.GREEN + Style.BRIGHT + "Update is Live!")
print(Style.RESET_ALL)
print(INDENT, datetime.now() - start_time)
@task(default=True)
def does_nothing():
print('this does nothing')
if __name__ == "__main__":
all_steps()
pelicanconf.py — Pelican Configuration
#!/usr/bin/env python
# -*- coding: utf-8 -*- #
import os
import sys
sys.path.append(os.curdir)
# Adam configuration options
ADAM_PUBLISH = False
from adamconf import *
# ADAM = True is used by the theme tempates to display 'Genealogy only' things
AUTHOR = 'D. Minchin & Wm. Minchin'
SITENAME = 'Minchin.ca'
if ADAM_PUBLISH:
SITEURL = 'http://minchin.ca/genealogy'
RELATIVE_URLS = False
else:
SITEURL = '.'
# Uncomment following line if you want document-relative URLs when developing
RELATIVE_URLS = True
SITE_ROOT_URL = 'http://minchin.ca'
TIMEZONE = 'America/Edmonton'
DEFAULT_LANG = 'en'
# Feed generation is usually not desired when developing
FEED_ALL_ATOM = None
CATEGORY_FEED_ATOM = None
TRANSLATION_FEED_ATOM = None
DEFAULT_PAGINATION = False
# static paths will be copied under the same name
# these are relative to the base CONTENT folder
STATIC_PATHS = ['images',
'../extras',
'css',
'design',
'js',
'pages/img',
'../.gitattributes',
'../.gitignore',
'../README.txt',
]
# A list of files to copy from the source to the destination
EXTRA_PATH_METADATA = {
'../.gitattributes': {'path': '.gitattributes'},
'../.gitignore': {'path': '.gitignore'},
'../README.txt': {'path': 'README.txt'},
'../extras/minchin.ico': {'path': 'favicon.ico'},
'../extras/.nojekyll': {'path': '.nojekyll'},
'js/tab-list-handler.js': {'path': 'tab-list-handler.js'},
'js/tooltip-handler.js': {'path': 'tooltip-handler.js'},
'js/graph-handler.js': {'path': 'graph-handler.js'},
'js/gigatrees-map-min.js': {'path': 'gigatrees-map-min.js'},
'pages/img/arrowd.png': {'path': 'arrowd.png'},
'pages/img/arrowl.png': {'path': 'arrowl.png'},
'pages/img/arrowr.png': {'path': 'arrowr.png'},
'pages/img/arrowu.png': {'path': 'arrowu.png'},
'pages/img/bg-black.png': {'path': 'bg-black.png'},
'pages/img/bg-pattern.png': {'path': 'bg-pattern.png'},
'pages/img/mapicon_f.png': {'path': 'mapicon_f.png'},
'pages/img/mapicon_m.png': {'path': 'mapicon_m.png'},
'pages/img/mapicon_u.png': {'path': 'mapicon_u.png'},
'pages/img/mapmarker1.png': {'path': 'mapmarker1.png'},
'pages/img/mapmarker2.png': {'path': 'mapmarker2.png'},
'pages/img/mapmarker3.png': {'path': 'mapmarker3.png'},
'pages/img/mapmarker4.png': {'path': 'mapmarker4.png'},
'pages/img/mapmarker5.png': {'path': 'mapmarker5.png'},
'pages/img/avatar.jpg': {'path': 'avatar.jpg'},
'pages/img/image.jpg': {'path': 'image.jpg'},
'pages/img/pdf.jpg': {'path': 'pdf.jpg'},
}
# Custom settings
FILENAME_METADATA = '(?P<slug>[\w-]*)' # so anything before the file extension becomes the slug
## Please note that the metadata available inside your files takes precedence
# over the metadata extracted from the filename.
MARKUP = (('rst',
'md',
'markdown',
'mkd',
'mdown',
'html',
'htm'))
PATH = 'content'
OUTPUT_PATH = '../genealogy-gh-pages/'
# Add Blog to sidebar
MENUITEMS = (('Blog', 'http://blog.minchin.ca/', 'fa fa-pencil'),
('Genealogy', SITEURL, 'glyphicon glyphicon-tree-deciduous'),
('My Projects', 'http://minchin.ca/projects/', 'fa fa-flask'),
('Search', 'http://minchin.ca/search/', 'fa fa-search'),
('About', 'http://minchin.ca/about/', 'fa fa-info-circle'),
('Contact Me', 'http://minchin.ca/contact/', 'fa fa-envelope'),
)
MENUITEMS_2_AT = 'Genealogy'
MENUITEMS_2_AT_LINK = '' # this is added to SITEURL
MENUITEMS_2 = (('Surnames', SITEURL + '/names.html', False),
('Updates', SITEURL + '/updates.html', False),
('Sources', SITEURL + '/sources.html', False),
('Distribution Map', SITEURL + '/map.html', False),
('Timelines', SITEURL + '/timeline.html', False),
#('Immigrants', SITEURL + '/immigrants.html', False), # doens't exist in current builds
#('Nobility', SITEURL + '/titles.html', False), # doens't exist in current builds
('Locations', SITEURL + '/places.html', False),
('Bonkers Report', SITEURL + '/bonkers-report.html', False),
('Photos', SITEURL + '/photos.html', False),
#('External Links', SITEURL + '/links.html', False), # doens't exist in current builds
#('Statistics', SITEURL + '/stats.html', False), # stats graphs aren't working right now
)
DISPLAY_PAGES_ON_MENU = False
# disable Tags, etc
TAGS_SAVE_AS = ''
TAG_SAVE_AS = ''
CATEGORY_URL = ''
CATEGORY_SAVE_AS = ''
CATEGORIES_URL = ''
CATEGORIES_SAVE_AS = ''
ARTICLE_URL = ''
ARTICLE_SAVE_AS = ''
AUTHORS_URL = ''
AUTHORS_SAVE_AS = ''
ARCHIVES_URL = ''
ARCHIVES_SAVE_AS = ''
PAGE_URL = "{slug}.html"
PAGE_SAVE_AS = "{slug}.html"
# Theme Related
TYPOGRIFY = False # turn off for HIDDEN names...
THEME = '../minchinweb.github.io-pelican/themes/pelican-minchin-ca'
SITELOGO = 'images/MinchindotCA-200.png'
SITELOGO_SIZE = '100%'
PYGMENTS_STYLE = 'friendly'
DISPLAY_BREADCRUMBS = True
FAVICON = 'favicon.ico'
BOOTSTRAP_THEME = 'minchin-ca'
USE_OPEN_GRAPH = True
CUSTOM_CSS = 'css/minchin-ca.css'
DOCUTIL_CSS = False
CUSTOM_JS_LIST = ['js/jquery-ui.min.js',
'js/globalize.min.js',
'js/dx.chartjs.js',
]
GOOGLE_ANALYTICS_UNIVERSAL = 'UA-384291-3'
GOOGLE_ANALYTICS_UNIVERSAL_PROPERTY = 'minchin.ca'
# Plugins
PLUGIN_PATHS = ('../pelican-plugins',)
PLUGINS = ['assets', ]
ASSET_CSS = False
ASSET_JS = False
SITEMAP = {
"format": "xml",
}
# # Make things disappear
DISPLAY_CATEGORIES_ON_MENU = False
HIDE_SITENAME = True
HIDE_SIDEBAR = True
FEED_ALL_ATOM = False
FEED_ALL_RSS = False
GITHUB_USER = False
ADDTHIS_PROFILE = False
DISQUS_SITENAME = False
PDF_PROCESSOR = False
adamconf.py — Additional Settings File
This settings file is generated by the build script (gen_upload.py) and then
imported into the Pelican configuration file (pelicanconf.py) to provide
these setting to Pelican.
# Genealogy Uploader, v.3.2.3
# C:\Users\William\Desktop\William 160108.ged
ADAM = True
ADAM_VERSION = "Built by Gigatrees (3.0.14)"
ADAM_UPDATED = "January 8, 2016"
ADAM_COPY_DATE = "1987-2016"
ADAM_LINK = "http://gigatrees.com"
ADAM_FOOTER = "<p><strong>Are we related?</strong> Are you a long lost cousin? Spotted an error here? This website remains a work-in-progress and I would love to hear from you. Drop me a line at minchinweb [at] gmail [dot] com.</p>"
ADAM_PUBLISH = True
Comments
There are no comments yet. Will you add the first one?